Publications
Selected Publications.
2025
- ICCV-Workshop
 Foundation versus Domain-specific Models: Performance Comparison, Fusion, and Explainability in Face RecognitionRedwan Sony, Parisa Farmanifard, Arun Ross, and Anil K. JainIn ICCV 2025 Workshop on Foundation and Generative Models in Biometrics, 2025
Foundation versus Domain-specific Models: Performance Comparison, Fusion, and Explainability in Face RecognitionRedwan Sony, Parisa Farmanifard, Arun Ross, and Anil K. JainIn ICCV 2025 Workshop on Foundation and Generative Models in Biometrics, 2025This work investigates the relative merits of foundation models and domain-specific models for face recognition. We present a systematic performance comparison across multiple benchmarks, explore fusion strategies to leverage complementary strengths, and propose explainability mechanisms for interpreting face recognition decisions. Our analysis highlights the trade-offs between generalization and domain specialization, demonstrating that while foundation models exhibit remarkable adaptability, domain-specific models often retain an edge in targeted biometric scenarios. Further, we show that fusing these models can enhance both recognition accuracy and interpretability, paving the way toward more robust and explainable biometric systems.
- arXiv
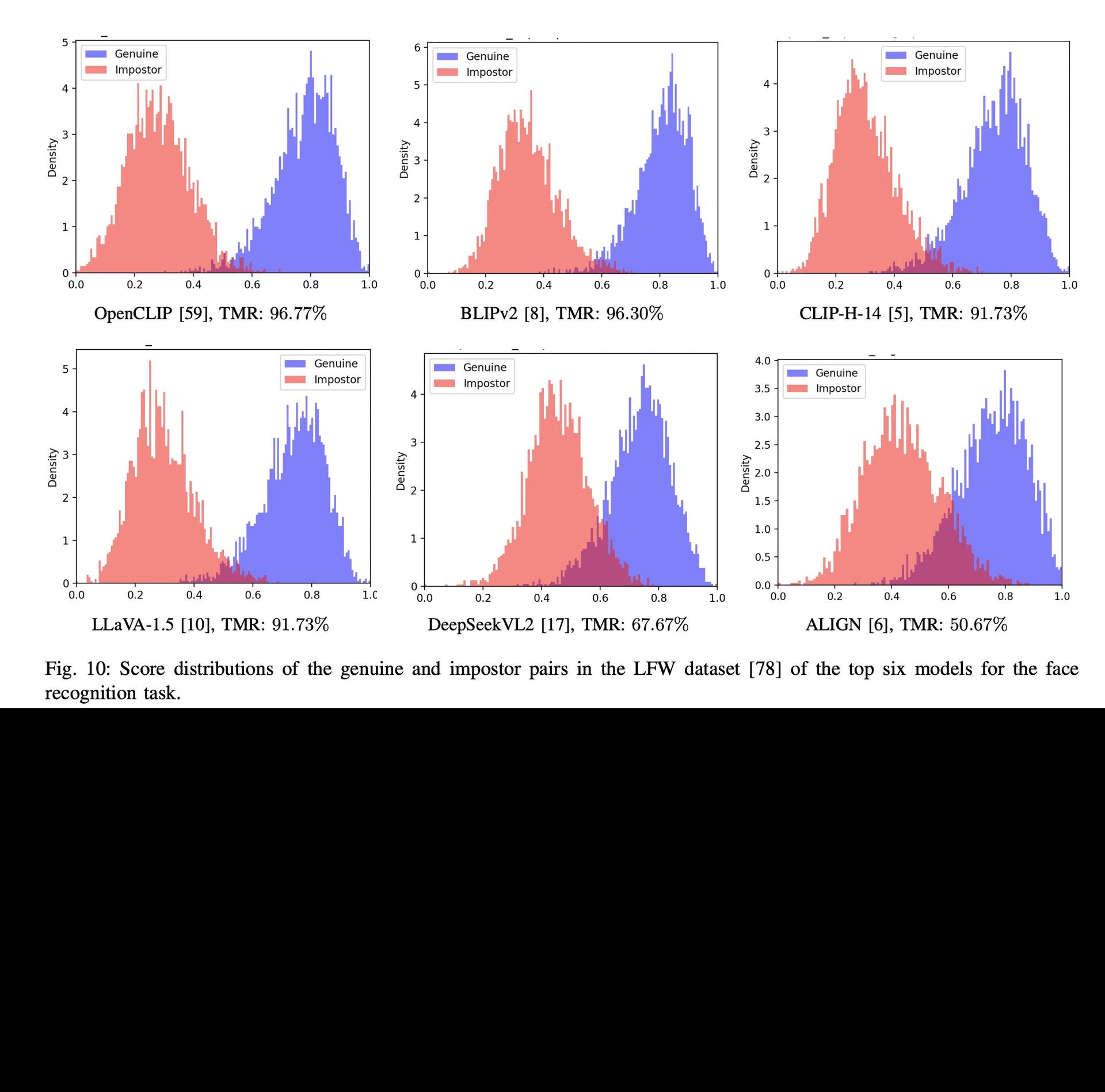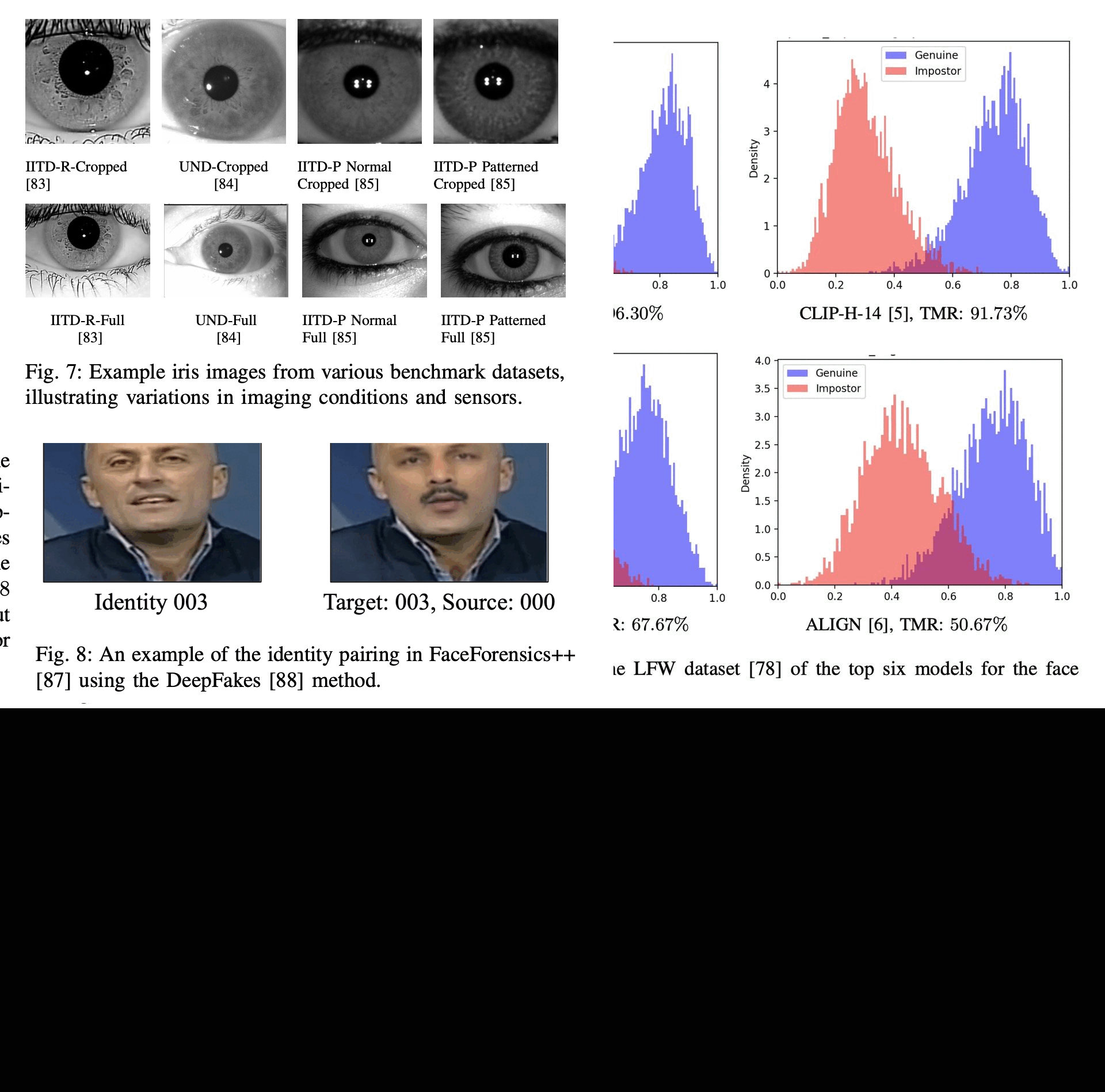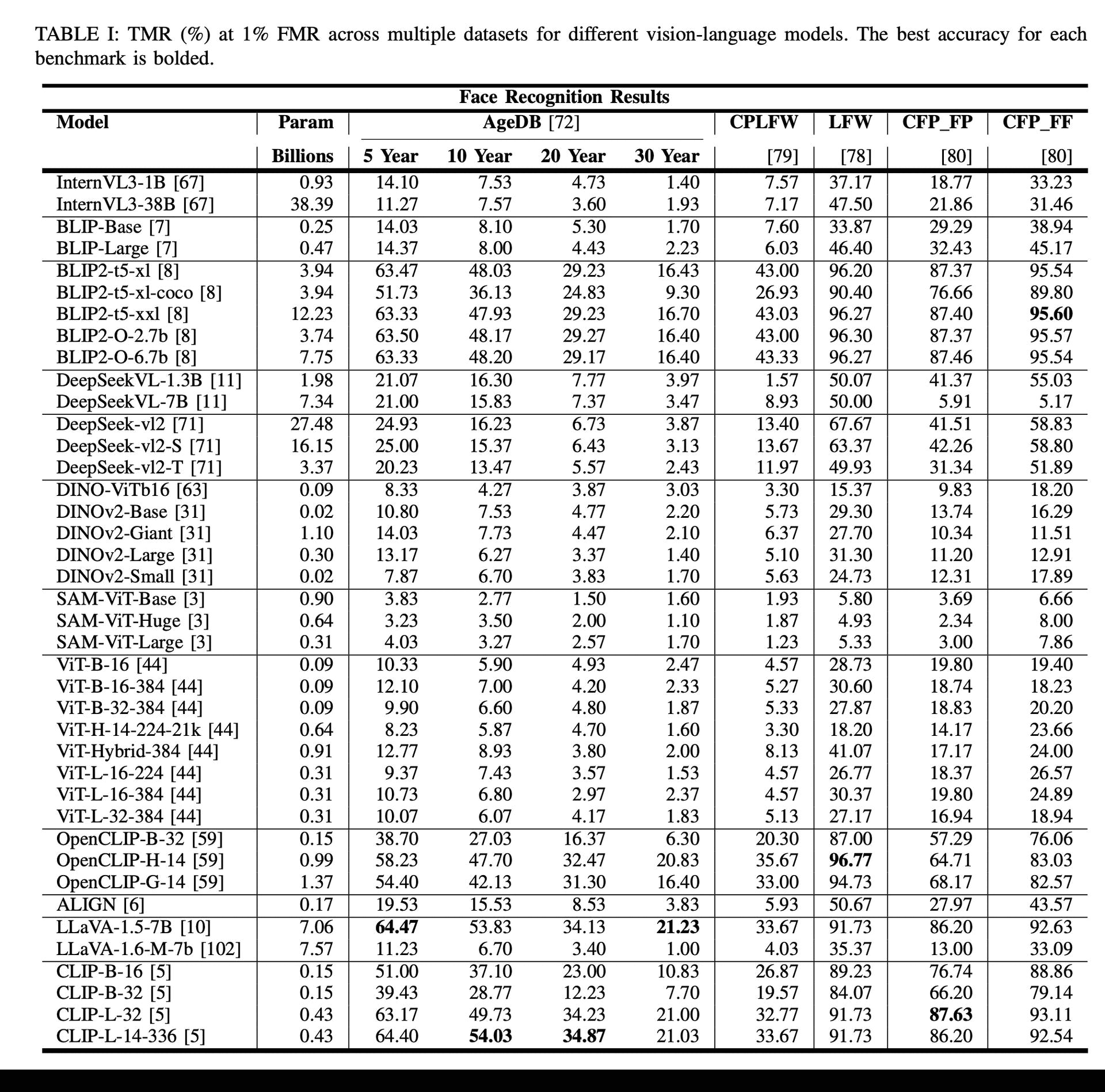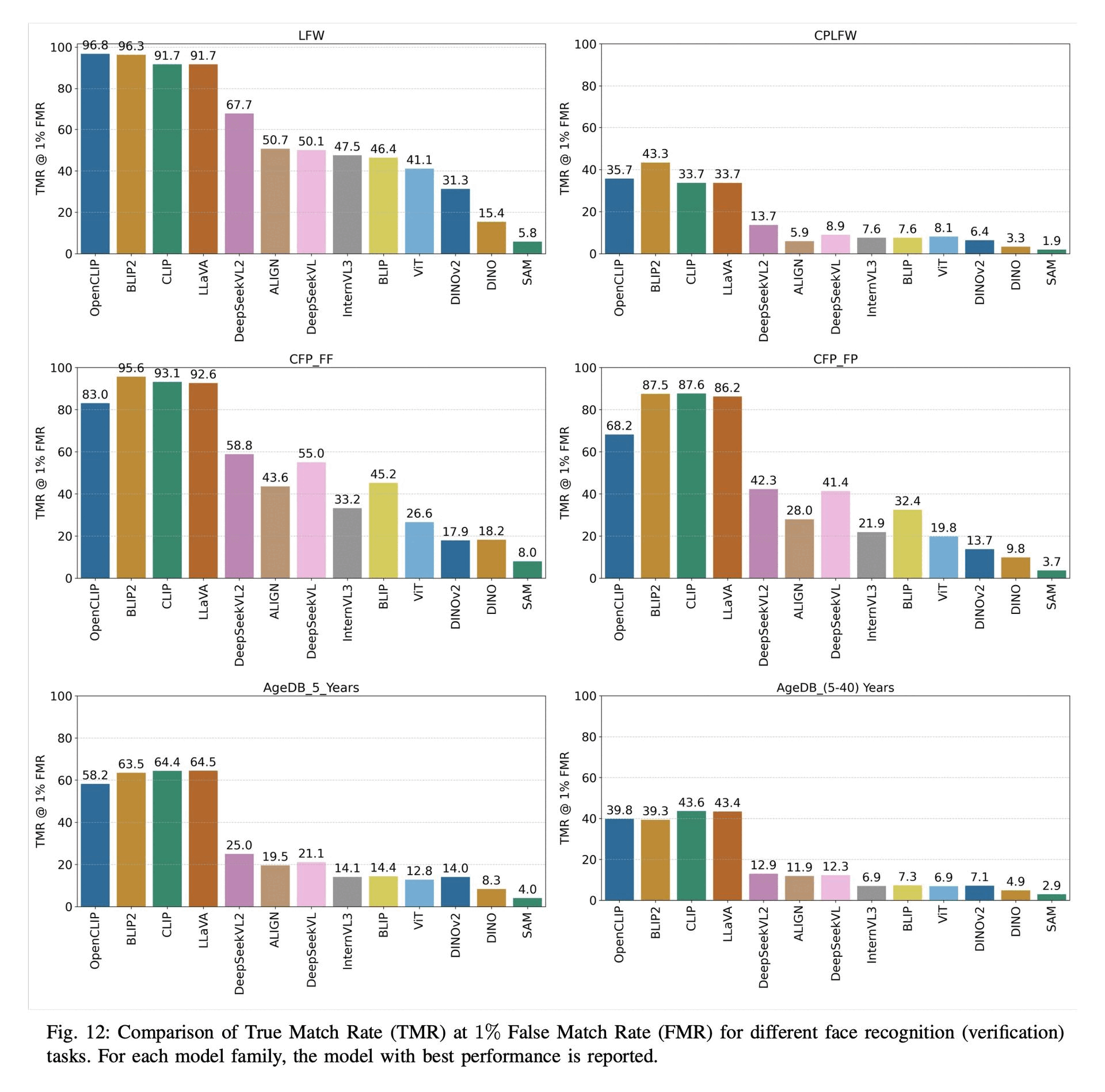 Benchmarking Foundation Models for Zero-Shot Biometric TasksRedwan Sony, Parisa Farmanifard, Hamzeh Alzwairy, Nitish Shukla, and 1 more authorIn arXiv preprint arXiv:2505.24214, 2025
Benchmarking Foundation Models for Zero-Shot Biometric TasksRedwan Sony, Parisa Farmanifard, Hamzeh Alzwairy, Nitish Shukla, and 1 more authorIn arXiv preprint arXiv:2505.24214, 2025The advent of foundation models, particularly Vision-Language Models (VLMs) and Multi-modal Large Language Models (MLLMs), has redefined the frontiers of artificial intelligence, enabling remarkable generalization across diverse tasks with minimal or no supervision. Yet, their potential in biometric recognition and analysis remains relatively underexplored. In this work, we introduce a comprehensive benchmark that evaluates the zero-shot and few-shot performance of state-of-the-art publicly available VLMs and MLLMs across six biometric tasks spanning the face and iris modalities: face verification, soft biometric attribute prediction (gender and race), iris recognition, presentation attack detection (PAD), and face manipulation detection (morphs and deepfakes). A total of 41 VLMs were used in this evaluation. Experiments show that embeddings from these foundation models can be used for diverse biometric tasks with varying degrees of success. For example, in the case of face verification, a True Match Rate (TMR) of 96.77 percent was obtained at a False Match Rate (FMR) of 1 percent on the Labeled Face in the Wild (LFW) dataset, without any fine-tuning. In the case of iris recognition, the TMR at 1 percent FMR on the IITD-R-Full dataset was 97.55 percent without any fine-tuning. Further, we show that applying a simple classifier head to these embeddings can help perform DeepFake detection for faces, Presentation Attack Detection (PAD) for irides, and extract soft biometric attributes like gender and ethnicity from faces with reasonably high accuracy. This work reiterates the potential of pretrained models in achieving the long-term vision of Artificial General Intelligence.
- WACV
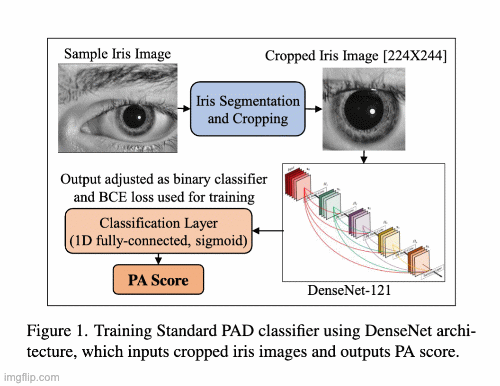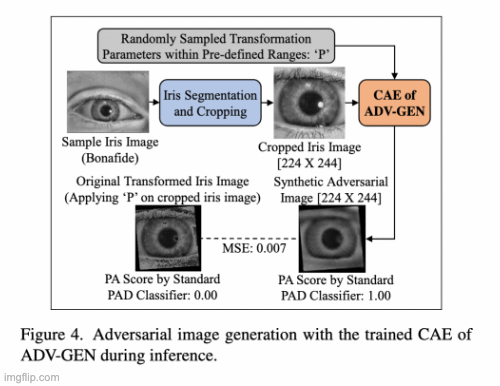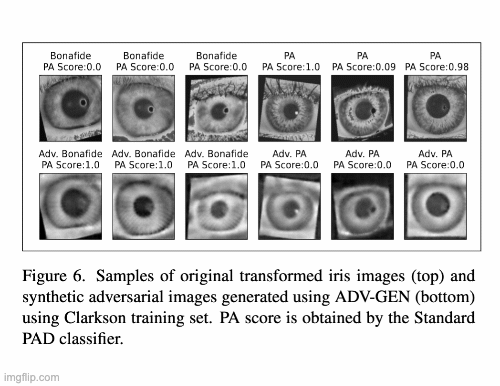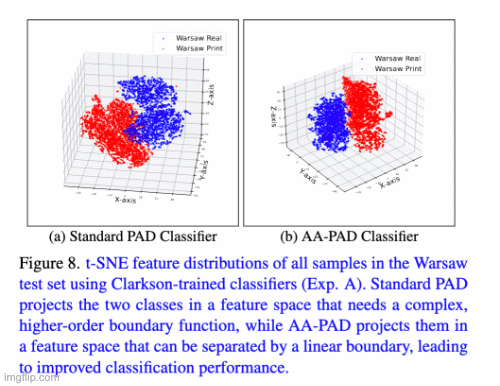 A Parametric Approach to Adversarial Augmentation for Cross-Domain Iris Presentation Attack DetectionPal Debasmita, Redwan Sony, and Arun RossIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025
A Parametric Approach to Adversarial Augmentation for Cross-Domain Iris Presentation Attack DetectionPal Debasmita, Redwan Sony, and Arun RossIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), 2025Iris-based biometric systems are vulnerable to presentation attacks (PAs), where adversaries present physical artifacts (e.g., printed iris images, textured contact lenses) to defeat the system. This has led to the development of various presentation attack detection (PAD) algorithms, which have demonstrated good performance in intra-domain settings. However, they often struggle to generalize effectively in cross-domain scenarios, where training and testing employ different sensors, PA instruments, and datasets. In this work, we use adversarial training samples of both bonafide irides and PAs to improve the cross-domain performance of a PAD classifier. The novelty lies in the method used to generate these samples. The proposed method leverages the transformation parameters used by classical data augmentation schemes (e.g., translation, rotation, shear). This is accomplished via a convolutional autoencoder, ADV-GEN, that utilizes original training samples along with a set of geometric and photometric transformations to produce adversarial samples. The transformation parameters act as regularization variables to guide ADV-GEN toward generating adversarial samples, which are then used in the training of a PAD classifier. Experiments conducted on the LivDet-Iris 2017 database, comprising four datasets, demonstrate the efficacy of this method in cross-domain scenarios.
- IEEE Access
 Automatic Comparative Chest Radiography Using Deep Neural NetworksRedwan Sony, Carolyn V. Isaac, Alexis Vanbaarle, Clara J. Devota, and 3 more authorsIn IEEE Access, 2025
Automatic Comparative Chest Radiography Using Deep Neural NetworksRedwan Sony, Carolyn V. Isaac, Alexis Vanbaarle, Clara J. Devota, and 3 more authorsIn IEEE Access, 2025Comparative medical radiography involves directly comparing antemortem (AM) and postmortem (PM) chest radiographs for human identification. In this work, we leverage deep neural networks and expert domain knowledge to develop a radiographic identification system based on 5,165 chest radiographs from 760 individuals, compiled from the NIH ChestX-ray14 database and Michigan State University Forensic Anthropology Laboratory (MSUFAL) case files. Expert-annotated regions of interest (ROIs)—thoracic vertebrae (T1–T5), clavicles, and the full vertebral column—were analyzed using ResNets, DenseNets, and EfficientNets. Results show that (a) the thoracic vertebrae (T1–T5) provide superior recognition accuracy, (b) EfficientNets outperform ResNets and DenseNets, and (c) ensembles across ROIs and architectures further improve performance. This is the first systematic assessment of ROIs for forensic radiography, and we release the annotated MSUFAL dataset and codebase to advance research in radiographic identification.
2024
- WACV Workshop
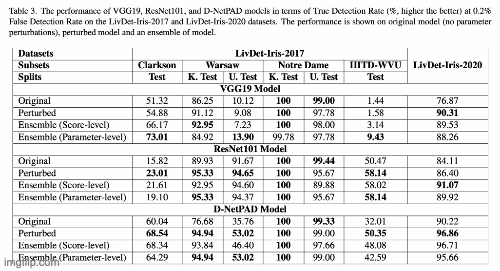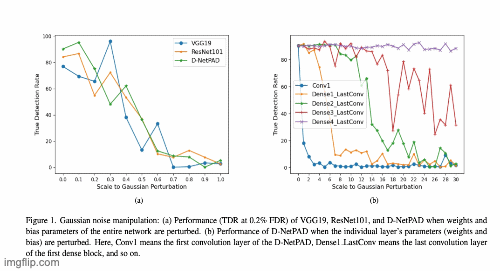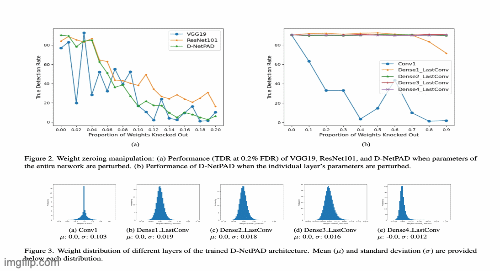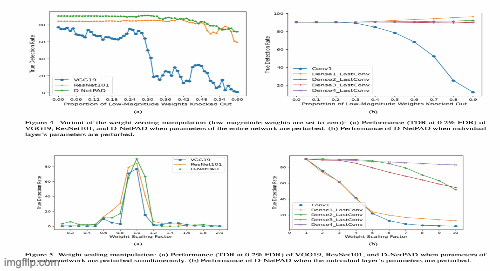 Investigating Weight-Perturbed Deep Neural Networks With Application in Iris Presentation Attack DetectionRenu Sharma, Redwan Sony, and Arun RossIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Workshops, Jan 2024
Investigating Weight-Perturbed Deep Neural Networks With Application in Iris Presentation Attack DetectionRenu Sharma, Redwan Sony, and Arun RossIn Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) Workshops, Jan 2024Deep neural networks (DNNs) exhibit superior performance in various machine learning tasks, e.g., image classification, speech recognition, biometric recognition, object detection, etc. However, it is essential to analyze their sensitivity to parameter perturbations before deploying them in real-world applications. In this work, we assess the sensitivity of DNNs against perturbations to their weight and bias parameters. The sensitivity analysis involves three DNN architectures (VGG, ResNet, and DenseNet), three types of parameter perturbations (Gaussian noise, weight zeroing, and weight scaling), and two settings (entire network and layer-wise). We perform experiments in the context of iris presentation attack detection and evaluate on two publicly available datasets: LivDet-Iris-2017 and LivDet-Iris-2020. Based on the sensitivity analysis, we propose improved models simply by perturbing parameters of the network without undergoing training. We further combine these perturbed models at the score-level and at the parameter-level to improve the performance over the original model. The ensemble at the parameter-level shows an average improvement of 43.58% on the LivDet-Iris-2017 dataset and 9.25% on the LivDet-Iris-2020 dataset.
2022
- IEEE Access
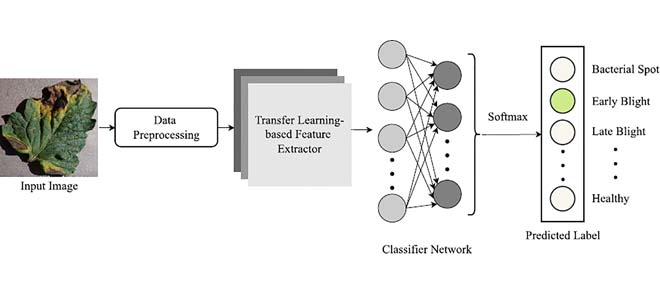 Less is More: A Lightweight and Fast Deep Neural Network for Tomato Leaf Disease ClassificationSabbir Ahmed, Md Bakhtiar Hasan, Tasnim Ahmed, Md Redwan Karim Sony, and 1 more authorIEEE Access, Jan 2022
Less is More: A Lightweight and Fast Deep Neural Network for Tomato Leaf Disease ClassificationSabbir Ahmed, Md Bakhtiar Hasan, Tasnim Ahmed, Md Redwan Karim Sony, and 1 more authorIEEE Access, Jan 2022To ensure global food security and the overall profit of stakeholders, the importance of correctly detecting and classifying plant diseases is paramount. In this connection, the emergence of deep learning-based image classification has introduced a substantial number of solutions. However, the applicability of these solutions in low-end devices requires fast, accurate, and computationally inexpensive systems. This work proposes a lightweight transfer learning-based approach for detecting diseases from tomato leaves. It utilizes an effective preprocessing method to enhance the leaf images with illumination correction for improved classification. Our system extracts features using a combined model consisting of a pretrained MobileNetV2 architecture and a classifier network for effective prediction. Traditional augmentation approaches are replaced by runtime augmentation to avoid data leakage and address the class imbalance issue. Evaluation on tomato leaf images from the PlantVillage dataset shows that the proposed architecture achieves 99.30% accuracy with a model size of 9.60MB and 4.87M floating-point operations, making it a suitable choice for low-end devices.
2018
- IUT JET
 Performance Comparison of Feature Descriptors in Offline Signature VerificationABM Rahman, MD Karim, Rafsanjany Kushol, and Md Hasanul KabirIUT Journal of Engineering and Technology (JET), Jan 2018
Performance Comparison of Feature Descriptors in Offline Signature VerificationABM Rahman, MD Karim, Rafsanjany Kushol, and Md Hasanul KabirIUT Journal of Engineering and Technology (JET), Jan 2018Handwritten Signature is a widely used biometric in daily life as a mean of identity verification of an individual. For offline signature verification both accuracy and speed are important parameters. Accuracy may vary as the samples from signature datasets show a high intra-class variability. As these properties depend on the feature descriptor taken to represent the signature image, this selection is very important. In this study we provide a comparative performance evaluation of wellknown histogram based descriptors like SIFT and SURF and a wide variety of binary descriptors like BRIEF, ORB, BRISK and FREAK in the application of handwritten signature verification. We compare the performance of these feature descriptors against speed and accuracy. After the experimental analysis we have observed that binary features like ORB is faster with moderate accuracy but SIFT-like descriptors give better accuracy. Among them the combination of FAST feature detection and BRIEF descriptor is the fastest one but with lowest accuracy.